Classification and Subject Access, Information Organization
What’s Happening in AI?
Student presentation — Week 6
Today
- Classification: What is it?
- Information Extraction: What is it?
- Subject access as a classification problem
- How to apply them: Easy / Better / Better-er / Best
- Coda: Data Analysis
What’s Happening in AI?
AI in the News: Poisoning the Water
Classification is showing up inside real evaluation systems:
- Hiring screeners can favor resumes produced by the same model doing the screening; simulations found same-model applicants were 23% to 60% more likely to be shortlisted than equally qualified human-written resumes (Xu et al., 2026).
- AI-generated peer review is becoming detectable at scale: one preprint estimates about 20% of ICLR reviews and 12% of Nature Communications reviews were AI-generated in 2025 (Shen & Wang, 2026).
AI in the News
- Frequent AI writing users can be unusually strong human detectors of AI-generated text; five “expert” annotators missed 1 of 300 articles in one study (Russell et al., 2025).
- Gen Z AI use is steady but more skeptical: 51% report daily or weekly use, while excitement fell from 36% to 22% and anger rose to 31% (Gallup, 2026).
Skill Check
From last week:
- How can AI tools help overcome the “vocabulary problem” in information seeking?
- What is RAG (Retrieval Augmented Generation) and how does it work?
- What are some strengths and limitations of using LLMs for information retrieval?
- List the different parts of the traditional search systems where AI can aid in information seeking.
- What are embedding models and how do they relate to traditional information retrieval approaches?
Key Concepts
Structured vs Unstructured Data
- Structured data: data that is organized in a predefined format, such as numbers, dates, and categorical variables.
- Unstructured data: data that is not organized in a predefined format, such as text, images, audio, and video.
Supervised vs Unsupervised Learning
Supervised Learning: Model learns from labeled training data
- Examples: Classification, regression
- Requires human-annotated data
- More accurate for specific tasks
- E.g., spam detection, sentiment analysis
Unsupervised Learning: Model finds patterns in unlabeled data
- Examples: Clustering, dimensionality reduction
- No human annotation needed
- Good for discovering hidden patterns
- E.g., customer segmentation, topic modeling
Classification
- Classification is the process of categorizing data into predefined categories or classes.
- It is traditionally a type of supervised learning, where the model is trained on labeled data.

As we'll see, few shot prompting of large pretrained models is changing how we approach it!
Information Extraction
- The process of extracting data from unstructured data
- Classification describes the data (metadata); Information Extraction extracts the data in some standardized format (content)
Some Use Cases
Classification
- Categorizing reference questions for service improvement
- Assigning subject headings, call number ranges, or local collection tags
- Classifying patron requests, chat transcripts, and ticket logs by service area, urgency, and referral pathway
- Mapping born-digital files to records series, retention categories, or disposition workflows
- Prioritizing digitization or preservation queues by demand, condition, rights complexity, and uniqueness
Some Use Cases
Information Extraction
- Extracting names, dates, places, and rights statements from archival descriptions
- Content analysis of research papers – e.g. extracting methodology types, research approaches, key findings, citations
- OCR for scanned newspapers, forms, ledgers, letters, and other digitized images so they become searchable text
- Pulling people, places, dates, events, and visual subjects from scanned photo captions, oral histories, finding aids, and accession records
- Accessibility: Creating draft object descriptions or alt text for photos, posters, maps, and ephemera while separating observed evidence from inference
- Converting legacy inventories and spreadsheets into structured fields for digital library or archives systems
The falling burden of training data
- Historically, training data was a limiting factor - you needed many examples, well-labeled
- Now, with generative AI, we can use fewer examples (few-shot) or even none (zero-shot)

Ad-hoc classification and few-shot expansion
With LLMs, we can do ‘on-the-fly’ classification, where we just describe it.
- e.g. “Here are books I liked …”
- -> “Suggest more”
- -> “Tag them by genre and rate them 1-5 on pulpiness, realism, etc.”
- -> “Write a taste profile for me”
* Ad-hoc: Created or done for a particular purpose as needed, rather than following a pre-existing system
Example from my research: classifying creativity tests

Results
Baseline
- Ranges from 0.12 (LSA, Semdis) - 0.26 (OCS)
LLM Prompted (c.2022)
Zero-Shot
- GPT-3 Davinci: .13
- GPT-3.5: .19
5-Shot
- GPT-3 Davinci: .42
- GPT-3.5: .43
Results (w/GPT-4 & Fine-Tuning)
Fine-tuning a model is better, but prompted models are rapidly improving.
Baseline
- Ranges from 0.12 (LSA, Semdis) - 0.26 (OCS)
LLM Prompted (adding GPT-4)
Zero-Shot
- GPT-4: .53 (vs. .19 for GPT-3.5)
5-Shot
- GPT-4: .66 (vs. .43 for GPT-3.5)
20-Shot
- GPT-4: .70
LLM Fine-Tuned
- T5 Large: .76
- GPT-3 Davinci: .81
How to do classification and information extraction
Easiest Way: Just Ask!
A clear prompt is all you need for many ‘good-enough’ results.
Questions to consider:
- What is the goal?
- How do you want the output to be structured?
- Classification: What are the labels? Is it categorical (discrete), ordinal (ranked), or continuous (numeric)?
- Data Extraction: What schema do you want to use? What properties do you want to extract?
Activity: Basic Sentiment Classification
Example Data
Tasks
- Classify the sentiment of tweets about a clothing company
- Extract topic categories for the tweets
Example: Tweets
A basic classification prompt:

Prompt:
Here is a set of tweets about a clothing company. Tag them by sentiment:
{tweets}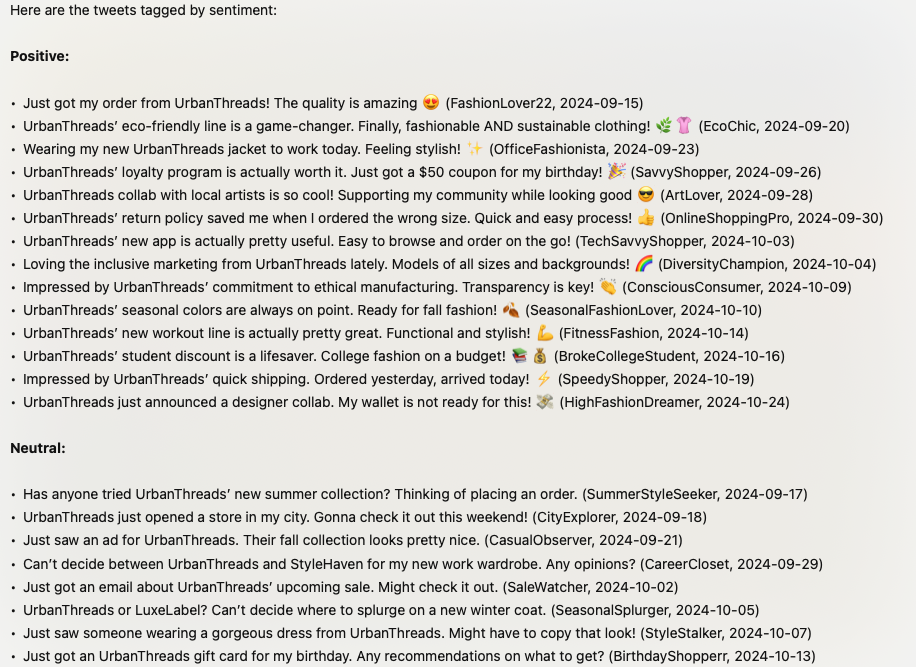
Improve the prompt with more guidance:
Here is a set of tweets about a clothing company.
Tag each one by sentiment on a scale of 1-5. 1 is negative, 3 is neutral, 5 is positive.
{tweets}
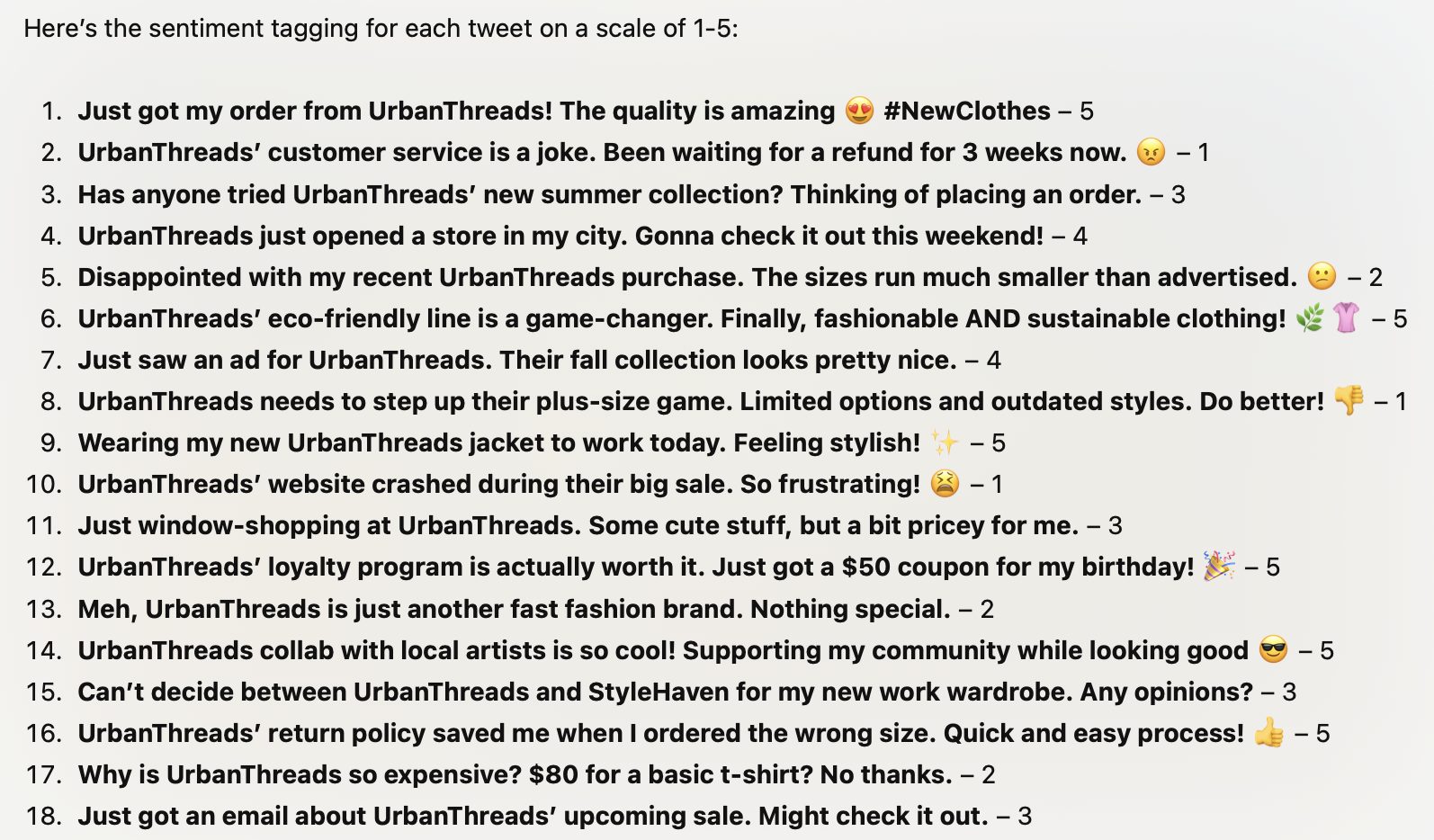
Even more guidance on labeling and few-shot examples and guidance on output format:
Here is a set of tweets about a clothing company. Tag each one by sentiment on a scale of 1-5. 1 is negative, 3 is neutral, 5 is positive.
# Coding Guidelines
## 1. Very Negative (1)
- Strong negative emotions (e.g., anger, frustration, sadness)
- Harsh criticism or complaints about UrbanThreads
- Use of negative words (e.g., "hate," "terrible," "awful")
- Negative experiences with UrbanThreads products or services
Example: "I absolutely hate UrbanThreads! Their clothes fell apart after one wash. Worst quality ever, never shopping there again! 😡 #UrbanThreadsFail"
... {and so on}
# Format
- [{score}] - {tweet}
# Tweets to Annotate
{tweets}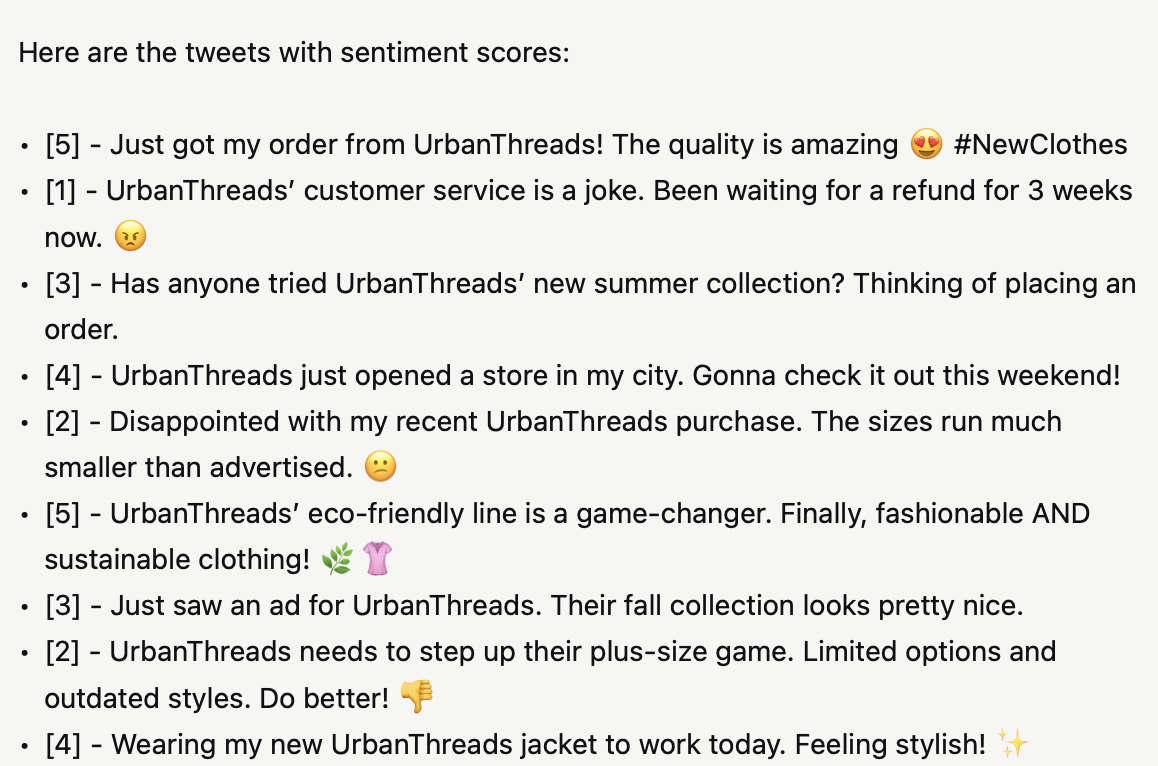
How to use it: Better
- Provide examples!! Just because zero-shot is good, don’t forget that few-shot is better
- Reasoning models can help when the classification depends on policy interpretation or evidence weighing
- Temperature (use the playground!)
- Structured Data Outputs
Temperature and Stochasticity
- Even at temperature = 0:
- Internal processes have some randomness
- Results may vary slightly between runs
- Newer models still show variation, and reasoning models are more likely to diverge since they use more tokens
- Think of it as:
- Temperature = intentionally added randomness
- Base randomness = inherent to model’s processes
Structured Data Outputs
Language models like structure. Be explicit.

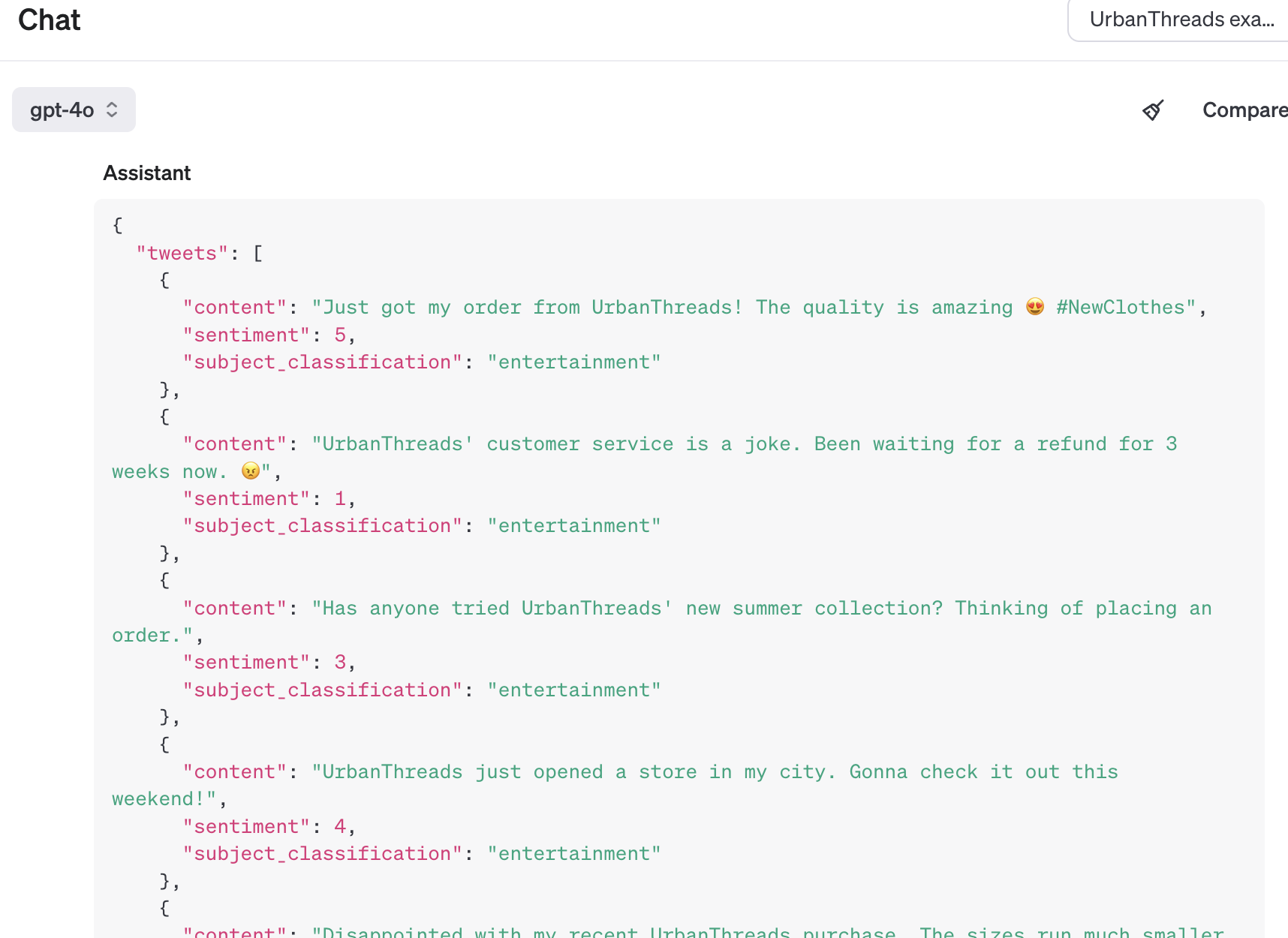
How to use it: Better-er
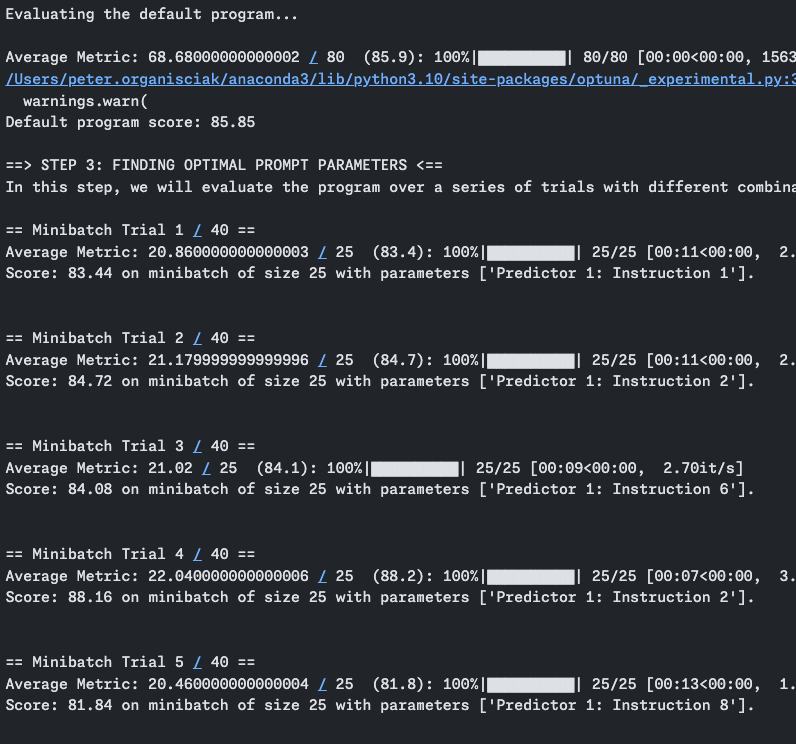
Prompt optimization
- Stop optimizing by vibes; use a validation set and compare errors (we’re going to do this in our Lab!)
- Treat the prompt, few-shot examples, output schema, and model choice as one pipeline
- Tools like DSPy can search over prompts/examples for repeated tasks
- For one-off work: write clear instructions and inspect outputs
- For repeated, high-stakes work: measure, hold out data, and iterate
How to use it: Best
Fine-tuning!
- Fine-tuning is the process of training a model on a specific task and dataset
- It is a type of supervised learning, where the model is trained on labeled data
- You’re training up from a language model, so the resource use is not prohibitive. E.g.
gpt-4o-miniorgpt-4o - the emergence of GenAI as an industry has made this much easier! You’re not coding neural networks, just uploading data of USER INPUT -> EXPECTED BOT RESPONSE

https://platform.openai.com/finetune
Buuuut… zero- and few- shot are so capable, that the benefits of fine-tuning only manifest for a) complex problems with lots of data to learn from, or b) making small (student) models that do something specific as well as a capable big (teacher) model
When do we want small AI models?
Coda: How do you get the data out of your chat bot?
Small one-off: use the chatbot tools
- Request “Write the data to a CSV file with Python”
- Python code will be generated and executed
- Inspect a few rows before trusting the file
Class lab: use the workbench
- It preserves prompts, results, scores, and raw model output
- It makes iteration comparable
Repeated work: use a pipeline
- API call
- Structured output
- Stored inputs and outputs
How do you get the data out, pt. 2
For bigger jobs, don’t rely on copying from a chat transcript. Use a workbench, an API, or an agent with files and logs.
We’ll cover agents next week.
Example output from ChatGPT:

Coda: Data Analysis
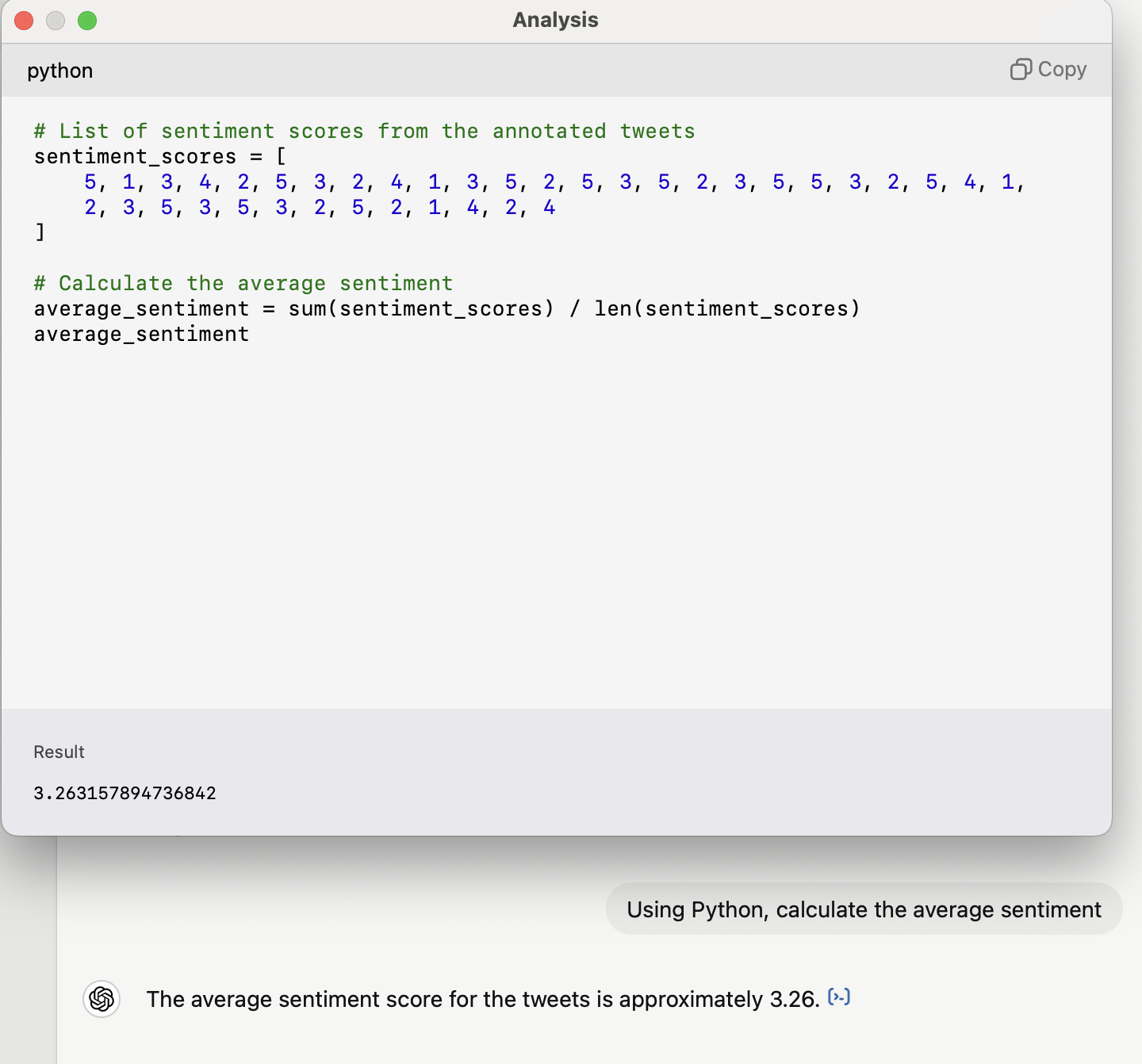
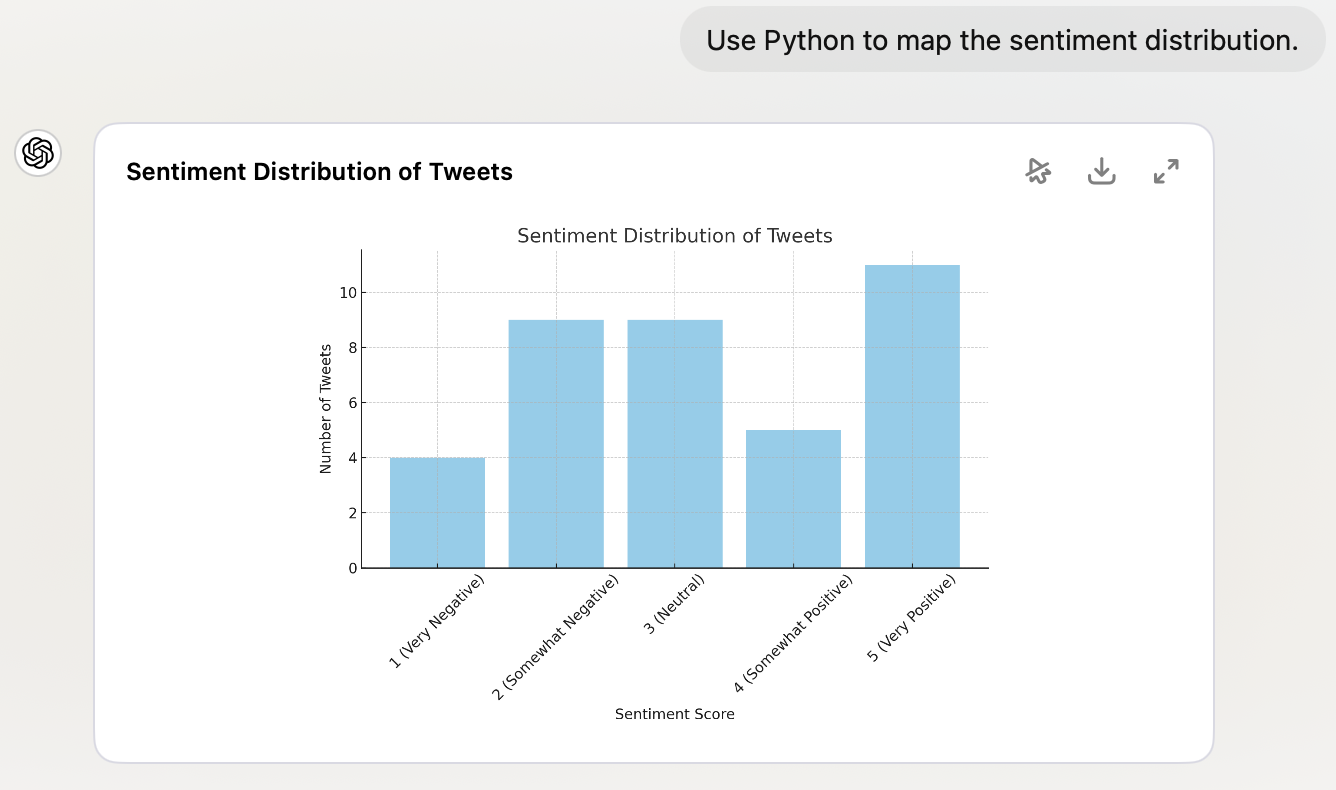
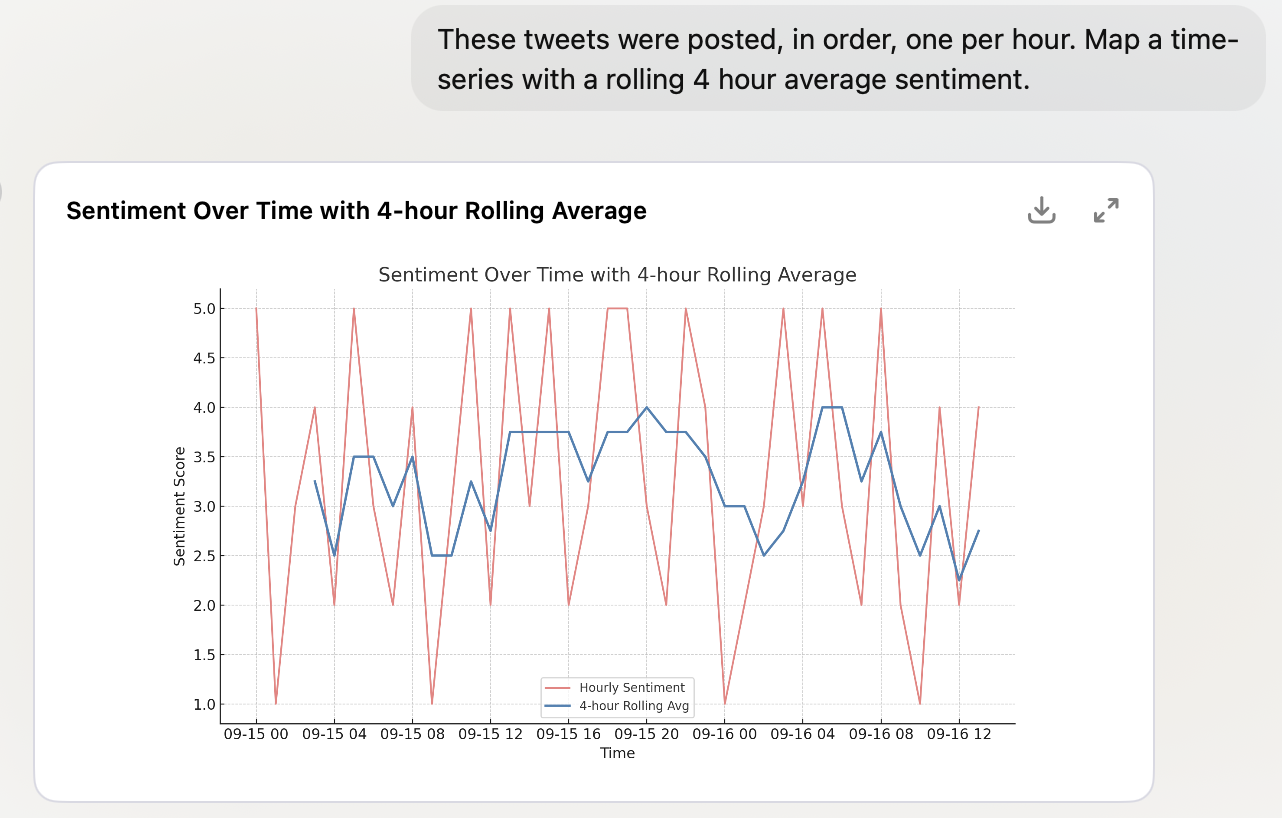
What do you do with the data once you have it?
Also use the code interpreter!
GPT can use Python, and Claude can use Javascript. But you don’t need to know Python or Javascript - it will write and run the code for you.
Summary
- Classification and Information Extraction are powerful tools for working with unstructured data
- Prompting with GenAI models, like ChatGPT or Claude - Just ask!
- Provide examples, specify your output, and clarify your schema
- For more trustworthy results:
- Use thinking/reasoning mode (built into GPT-5, Claude extended thinking, Gemini Deep Think)
- Use temperature=0
- Use structured outputs
- Fine-tune your own models
Questions?
Lab: Classification Prompt Battle
You’ll be writing prompts to ask a larger language model to score data against a dataset.
Lab Details: https://ai.porg.dev/labs/classification
Use the following page for classification: