AI in Society
The challenges and ethics of AI use - considering it’s outward effects
Question
What have you used LLMs or other AI for in the past week?
Lab Discussion: Bias Analysis
Reflecting on Your Experiments
- Which models did you test, and why did you choose them?
- What surprised you most about your findings?
- Did any model perform significantly better or worse than you expected?
Counterfactual Prompting Results
- What demographic variables created the most noticeable differences in outputs?
- Were there subtle differences in tone or framing that revealed potential biases?
- How consistent were the biases across different types of prompts?
Role Reversal Insights
- Did models rely on stereotypes when generating content from different perspectives?
- Where did models draw the line on role-playing certain identities?
- How did “uncensored” models differ from mainstream ones in this exercise?
Synthetic Data Analysis
- What patterns emerged in your synthetic data generation?
- How effective was the model at identifying its own biases in the data?
- Did the model’s bias analysis align with your human evaluation?
Broader Implications
- What policy challenges do these biases raise?
- What responsibility do model creators have to mitigate these biases?
- What regulatory approaches might address the issues you discovered?
Challenges of Use
Bad Operators
There are many possible unethical uses of AI - not inherent to the technology, but to it’s applications
- e.g. cheating, spam, harrassment, misinformation, content farming, etc.
Exercise: Where Do We Draw the Line?
In groups of 3-5, collaboratively generate three distinct AI use cases, considering ‘good/bad/borderline’ from the perspective of ethics, safety, and risk
- Clearly Ethical (“Good”): An AI use case where benefits are obvious and risks minimal
- Clearly Unethical/Inappropriate (“Bad”): A use case where the negative impact or misuse is evident
- Borderline/Gray Area: A scenario that isn’t immediately obvious and could be seen as both ethical and problematic
Step 2: Sharing your responses
Paste your list, in no particular order, into the spreadsheet (link shared in class)
Step 3: Voting
Let’s take a 3 minute break, while I randomize the list and paste into Mentimeter - then we vote!
Discussion/Debate
AI Slop
Slop describes AI-generated content that is both unrequested and unreviewed.
Problems with Machine Learning in the Real World
Non-malicious edition
- Too bad classification
- A classifier for finding criminals with 99.9% precision can cause a lot of trouble for that final 0.1% - especially if we trust the hits more than misses.
- Too good classification
- Identifying pseudonymous authors
- Identifying sexual orientation
- Learning the private from the public
- scraping public OKCupid profiles
- political leaning extraction
- Decision-making from incomplete or imperfect information
Accountability Gap
- Unaccountability of black boxes
A person can hide behind a machine’s opaque set of decisions (the accountability gap)
- e.g.
- easier to reject a job applicant if text mining their social media
- easier to assign a poor grade if the essay marking bot says so
- e.g.
Rules for your applications
- Code of ethics
- Rules aren’t always clear cut, but give you a framework to think about potential problems
- e.g. @CancelThatCard vs. @NeedADebitCard
- Showing and explaining the decisions of a system
- EU GDPR: data controllers must disclose significance and envisaged consequences in clear and plain language (Mittelstadt et al. 2016)
- Coders/designers taking responsibility for algorithms
- Don’t hide behind your algorithm’s choices
Challenges of communicating what a model is to a user
Should LLMs talk like people? Should a text model say ‘I’?
Anthropic, on Claude’s ’Character Training‘:
Adopting the views of whoever you’re talking with is pandering and insincere. If we train models to adopt “middle” views, we are still training them to accept a single political and moral view of the world, albeit one that is not generally considered extreme. Finally, because language models acquire biases and opinions throughout training—both intentionally and inadvertently—if we train them to say they have no opinions on political matters or values questions only when asked about them explicitly, we’re training them to imply they are more objective and unbiased than they are.
We want people to know that they’re interacting with a language model and not a person. But we also want them to know they’re interacting with an imperfect entity with its own biases and with a disposition towards some opinions more than others. Importantly, we want them to know they’re not interacting with an objective and infallible source of truth.
About the Model
Environmental Costs
Framing -> Model training vs. inference (i.e. when you use a trained model) -> Individual models vs. the industry
Inference Costs
The environmental cost of use (i.e. your specific prompt) is small, and plummeting.
- GPT-3 Davinci in Mar 2022: $60.00/1M tokens
- GPT-4o-mini in Feb 2024: $0.15/1M tokens

Some estimates on a ChatGPT prompt is 3wh, based on some (likely overestimated) suggestions that a prompt is equal to 10 Google searches.
CO energy cost is about 13c/Kwh - so 2500 prompts per dollar of energy.
Other notes:
- a prompt is equivalent about 3 minutes of laptop use or 1.2 minutes of refridgerator use
- consider costs - with chatbots ranging from free to $20, companies are not providing access to systems requiring hundreds of dollars of energy
Training
- Training: the process of creating a model
Big models with disclosed CO2 costs:
- GPT-3: 608 tonnes CO2eq emissions
- Llama 2: 539 tonnes CO2eq emissions
Comparison:
- Boeing 747: ~35 tonnes CO2/hour (i.e. ~525 tonnes round trip NYC to London)
- US per-capita annual fossil fuel emissions (2023): 14.3t CO2/year
Aggregate-level Costs
Problem: It’s not just one company training models.
OpenAI, Microsoft, Amazon, Alphabet, Meta, Anthropic, Alibaba, Deepseek, etc…
Problem #2: Companies are tooling for an large resource-use future (Deepseek news tempers this?)
In sum
Environment impact estimates are tricky, because:
- It’s not just a single model in isolation
- information is vague on the backend use (e.g. R&D, test model training, etc.)
- Energy use is electric, and electric grid impact is variable by region and data center
- And physical resources are very complex to estimate (e.g. mining costs for GPUs, energy use of production, etc.)
A few things we know
- costs (environmental and real) are falling
- There are massively inflated bad-faith points out there
- Lots of redundancy in the industry
- A prompt for a trained model is low impact
- Better hardware is more efficient - improving our chips reduces wasted energy
Labor
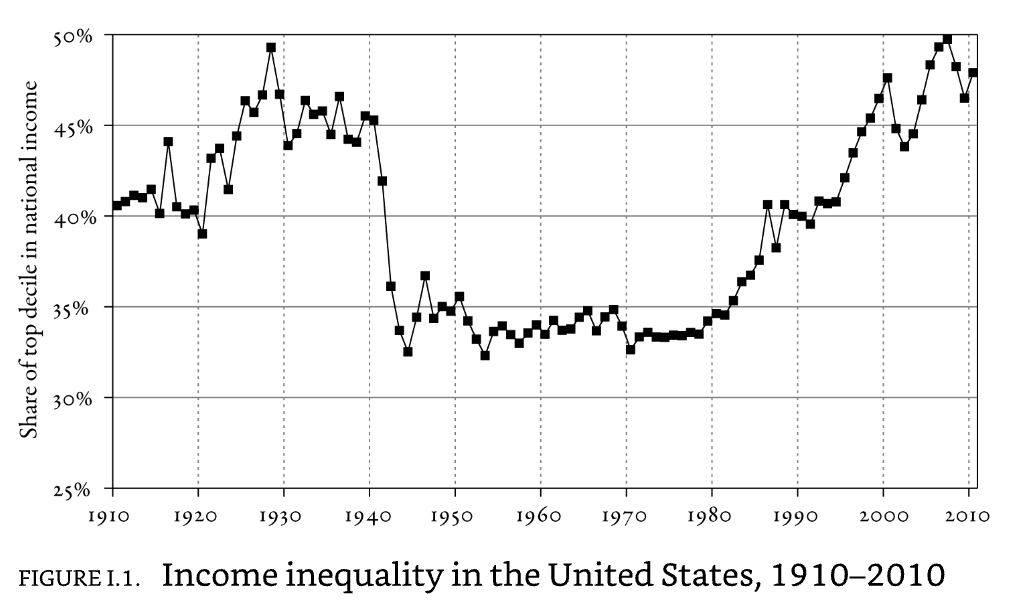
(Picketty 2014)
Over a long period of time, the main force in favor of greater equality has been the diffusion of knowledge and skills. (Piketty 2014)
Is AI a skilling or de-skilling technology?
AI’s Impact on Workers
The ‘jagged technological frontier’ - productivity gains are unevenly distributed, as are impacts
Concerns:
- Job Displacement: Automation of routine cognitive tasks
- Skill Shifts: Increasing demand for AI-adjacent skills
- Wage Depression: Downward pressure on wages in affected sectors
- Skill Devaluation: Devaluing expertise as AI systems appear to replicate it