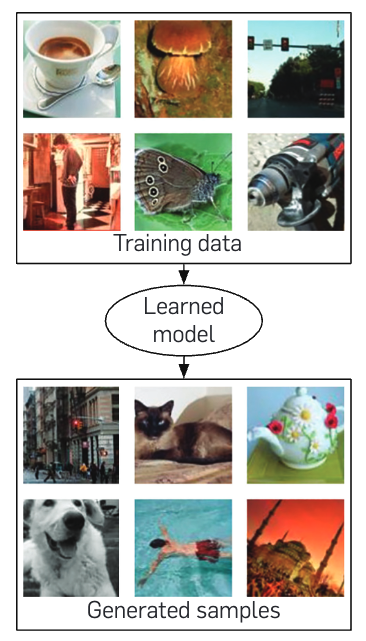
Multimodal Models
Introduction to Multimodal AI
AI systems that process and generate multiple types of data (text, images, audio, video)
Text-to-Image Models
- Key milestones:
- GANs → Diffusion Models → Transformer-based approaches
- CLIP (Contrastive Language-Image Pre-training)
- ViT (Vision Transformer)
- DALL-E and its iterations, Stable Diffusion, Midjourney
- GPT-4v - and combining transformers with vision transformers
Let’s discuss these in turn.
Generative Adversarial Networks (GANs, 2014)
GANs are a type of generative model that uses two neural networks:
- A generator network that generates fake data
- A discriminator network that tries to distinguish between real and fake data
For images, the generator network takes a random noise vector and generates an image. The discriminator network takes an image and tries to determine if it’s real or fake.
CLIP (Contrastive Language-Image Pre-training, Radford et al., 2021)
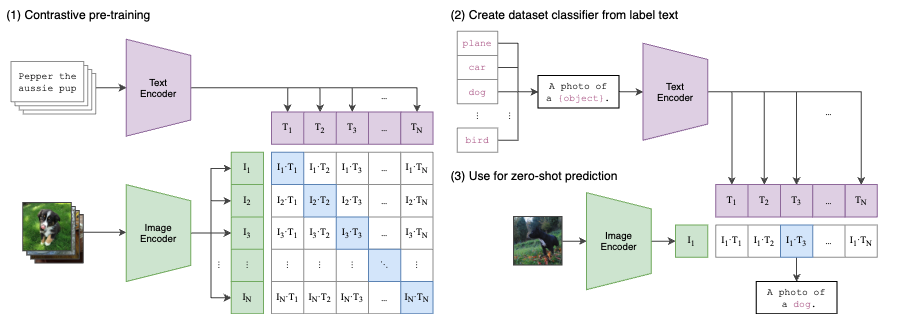
CLIP is a multimodal model that understands the relationship between text and images.
It’s not a generative model - it allows you to measure the similarity between text and images
LatentScape: Explore a Latent Image Space

Take a moment to think about this
Why would a model that measures distance between text and images be useful in generating images?
Think back to the GAN ‘discriminator’ network.
Having a measurable relationship between an image and text means you can start training a generator, and automatically score if it’s generating good or bad images.
You can use that as a reward to train your generator.
Before we consider generative models, let’s discuss what else we can do with CLIP
DALL-E (OpenAI, 2021)
DALL-E 1 is a text-to-image generation model that uses CLIP and a trained transformer model.
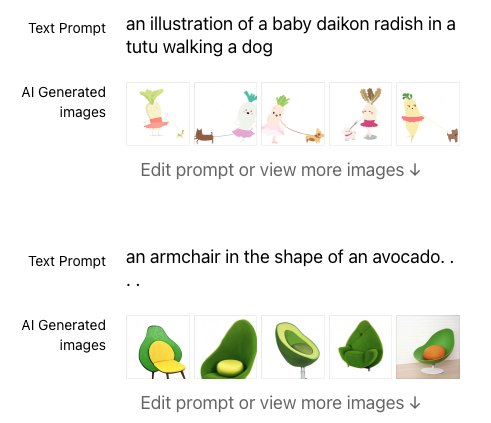
Subsequent versions of DALL-E were 'diffusion' models, which generate 'noise' that is iteratively refined into an image.
Other Generation Models
- Stable Diffusion
- Midjourney
- Ideogram
- Gemini
- FLUX



Images: an SDXL fine-tune
Sora

Oasis

Beyond Generation
This is an AI literacy class. How is this something that we end up using?
Unlike with text where generative models proved to be extremely useful, with visual language the generative capabilities tend to be more fun or specialized (e.g. art and film; stock photography).
Visually, interpretive capabilities tend to be more broadly practically useful.
Vision Transformers
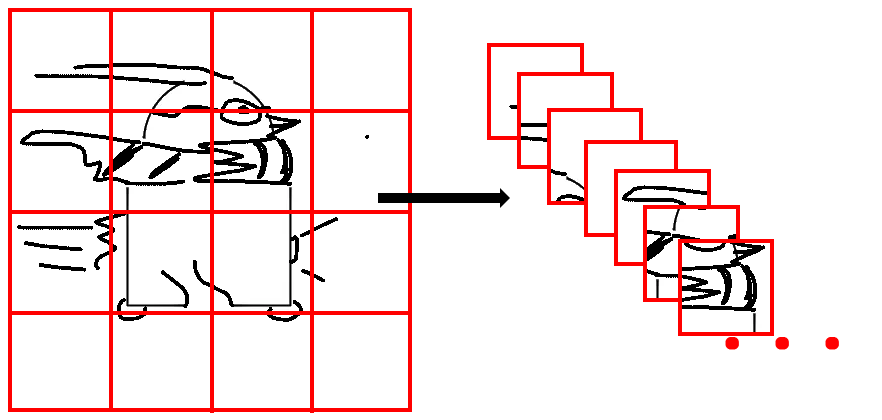
Vision Transformers (ViT; Dosovitskiy et al. 2020) are a type of transformer model that are specifically designed to process images.
DALL-E was a transformer-based *autoregressive* (i.e. decoder-only generative model) model - here, we're talking about an *encoder* model - which can be used to understand images.
The Vision Transformer approach makes clear that images can be treated the same way as text, so why not use them together?
GPT-4V (OpenAI, 2023); Claude 3 Vision (Anthropic, 2024); Gemini (Google, 2023); LLaMA 3 (Meta, 2024)
What makes this composition particularly compelling is the juxtaposition of the dog’s natural solemnity against the playful absurdity of being dressed as the very food item that shares its colloquial name.
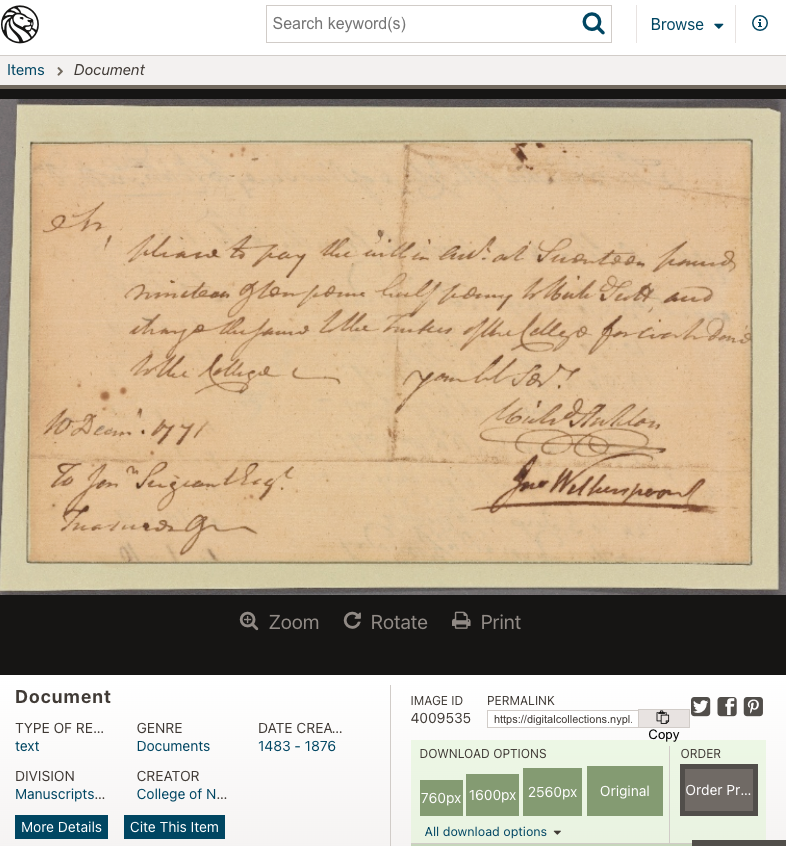
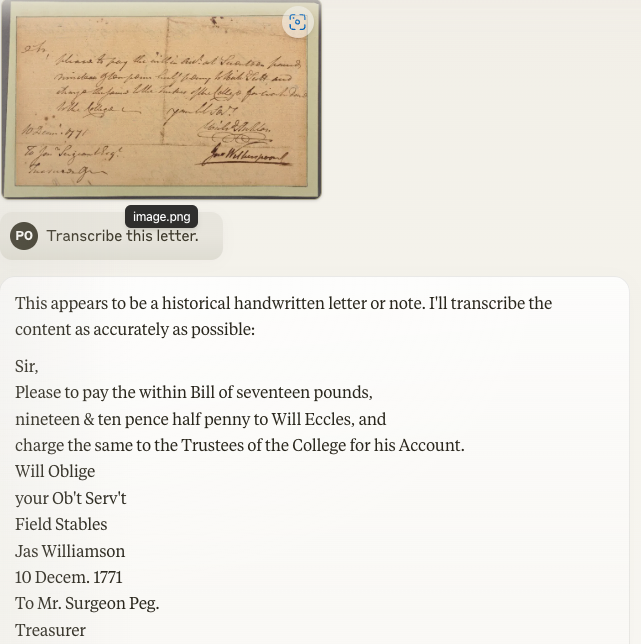
Order on Jonathan Sergeant, Treasurer, to pay £17 19s. 10 1/2 d. to Richard Scott, for work done about the college, according to the within account.
What do we use it for?
- Image classification and recognition
- Object detection and segmentation
- Scene understanding and visual reasoning
- Zero-shot visual recognition
- Accessibility
… And just like that…

Short Exercise: Try GPT Voice Mode
In groups of 3-4, try out the new voice mode in GPT-4o, around one phone (onsite) or following with a single group leader (on Zoom)
Creative Applications


Whisk: Example of clever application design
- Generating images based on example style, scene, and subject images
- Using analyzed text descriptions from examples to create prompts
- Demonstrates how application design can simplify complex technology

Suno
MusicFX
Ethical Considerations
- Image rights and copyright challenges
- Deepfakes and potential misuse
- Consent and privacy issues
- Bias and representation issues in generated imagery
- Content safety measures and limitations

Is It a Tool or an Fake Artist?
Consider:
- Bad AI art doesn’t preclude good art with AI in your toolkit
- How artists leverage AI tools for creative expression
- The interplay between human direction and AI capabilities
- Practical approaches to using AI in creative workflows
Lab: AI Art Exhibition and Critique
Updates
Updates since I last taught the class are here. They are not formatted as slides, so refer to the ‘Notes’ version of the deck https://ai.porg.dev
- Native Image-Generation
- March 2025: gpt-4o can finally create images -> overcomes many problems of earlier image generators.